

I Rebuilt My Professional Brand for AI. It Cost $0.
You should be courting chatbots, but not the way that you think.

Open an incognito window and ask ChatGPT about yourself. Ask Claude, Perplexity, or Gemini. Your LLM of choice, really.
What did you get back?
When I opened an incognito window a few months ago and made the rounds of asking various LLMs about myself, I was a bit dismayed at the results. The models knew I existed, kind of, but all had varying answers to who I was. ChatGPT thought I was a 3-year-old girl who disappeared nearly 30 years ago.
The other models could associate me with marketing and e-commerce, but vaguely. None had any idea what I specialize in professionally, couldn’t connect me to my publication, and didn’t surface any of the work I’d published over the past several years. A decade of LinkedIn, a personal website that’s been live since college, various blogs and social media platforms — I’ve been a millennial online since I sat down at our first living room computer in 1997 — and each AI could only assemble a sketch that could’ve described ten thousand other people.
So I went into research mode, and started asking questions.
“How can I train AI models to speak about me?”
“What do I want it to say about me?”
What progressed from there was a research deep dive, strategy development, and a lot of querying. I understood how to design an AEO strategy for B2C and B2B brands and have run those programs, but I wasn’t sure would or wouldn’t be translatable to optimizing for a person.
What I found to be the largest contributing issue was the infrastructure underneath my content. My professional brand was scattered across platforms that were never designed to talk to AI crawlers, and none of them expose the structured data that LLMs need to connect a person to their work.
So I started building the structural layer to fix it. An edge proxy that injects Person schema onto every Substack page. An llms.txt file. A cross-platform entity audit. The whole build cost $0/month and took about two weeks of focused work, followed by maintenance, tweaks, and analysis.
Now, 90 days later and having reached what I would consider stat sig, the results from each LLM are significantly improved.
In this piece I’m going to walk you through what AEO actually is, why it is different from SEO, why the platforms you’re on are structurally hiding you from AI, how I added structured data to my personal site and Substack, how I got AI platforms to correct factual errors about me, and a simple workflow you can implement today with zero budget.
Let’s dive right into it then…
SEO, but for AI: what is AEO?
SEO (Search Engine Optimization) is the practice of making your website show up in Google. You’ve heard of it. You probably have opinions about it. AEO (Answer Engine Optimization) is the same idea applied to AI: making sure that when someone asks ChatGPT, Claude, Perplexity, or Google about you or a question you’re qualified to answer, they can actually find you.
The structured data format that matters most is called JSON-LD (JavaScript Object Notation for Linked Data). It’s a block of code that sits in the <head> of your webpage, largely invisible to human readers, that describes you in a format AI can parse. Schema.org defines the vocabulary — Person, Organization, FAQ, Article — and the properties within each: your name, job title, areas of expertise, links to your other profiles.
If you’ve ever wondered why some people show up in AI answers and others don’t, this is usually why.
Why your platforms are hiding you from AI
The core problem: if your professional presence lives entirely on platforms you don’t control, you can’t give AI what it needs to find you.
LinkedIn doesn’t expose your profile data as structured schema to competing AI systems. (Of course it doesn’t. Why would it hand your professional graph to ChatGPT?) Substack doesn’t let you inject JSON-LD into your page headers. Medium, Beehiiv, Ghost hosted: same story. These platforms were designed for human readers and Google’s traditional crawlers.
AI crawlers read raw HTML, and most of them don’t execute JavaScript. They’re looking for structured data, specifically JSON-LD schema that’s largely invisible to human readers, that tells them in machine-readable format who you are, what you know, and where else you exist on the internet. If that data isn’t in the HTML, the crawler sees content without context. It might index your Substack posts, but it has no way to connect them to you as an entity.
Traditional SEO solved this for companies with Product schema, Organization schema, LocalBusiness schema. The professional equivalent is Person schema.
This really matters at scale. AI-driven traffic nearly tripled over the course of 2025, growing 8x faster than human traffic. Your audience, whether they’re recruiters, prospective clients, journalists, podcast producers, etc — they’re using ChatGPT and Perplexity to research people before they ever open a LinkedIn profile. If you’re a creator, founder, or consultant, these systems are already evaluating you, whether you’ve given them anything structured to work with or not.
Even when AI can read your content, it reads selectively. An analysis of 1.2 million verified ChatGPT citations found that 44.2% of all citations come from the first 30% of text on a page, which makes sense if you’re thinking about managing context or token usage. AI reads like a journalist on deadline — it grabs the lede. If your strongest expertise claims live in a bio at the bottom of your website or buried in your Substack “About” page, the AI never gets to them.
The playbook: Teach AI who you are
AI is blind without structured data. We’ve talked about this a lot here already. My personal site is built on Framer, which gives me full control over the <head>. I added three layers of JSON-LD structured data:
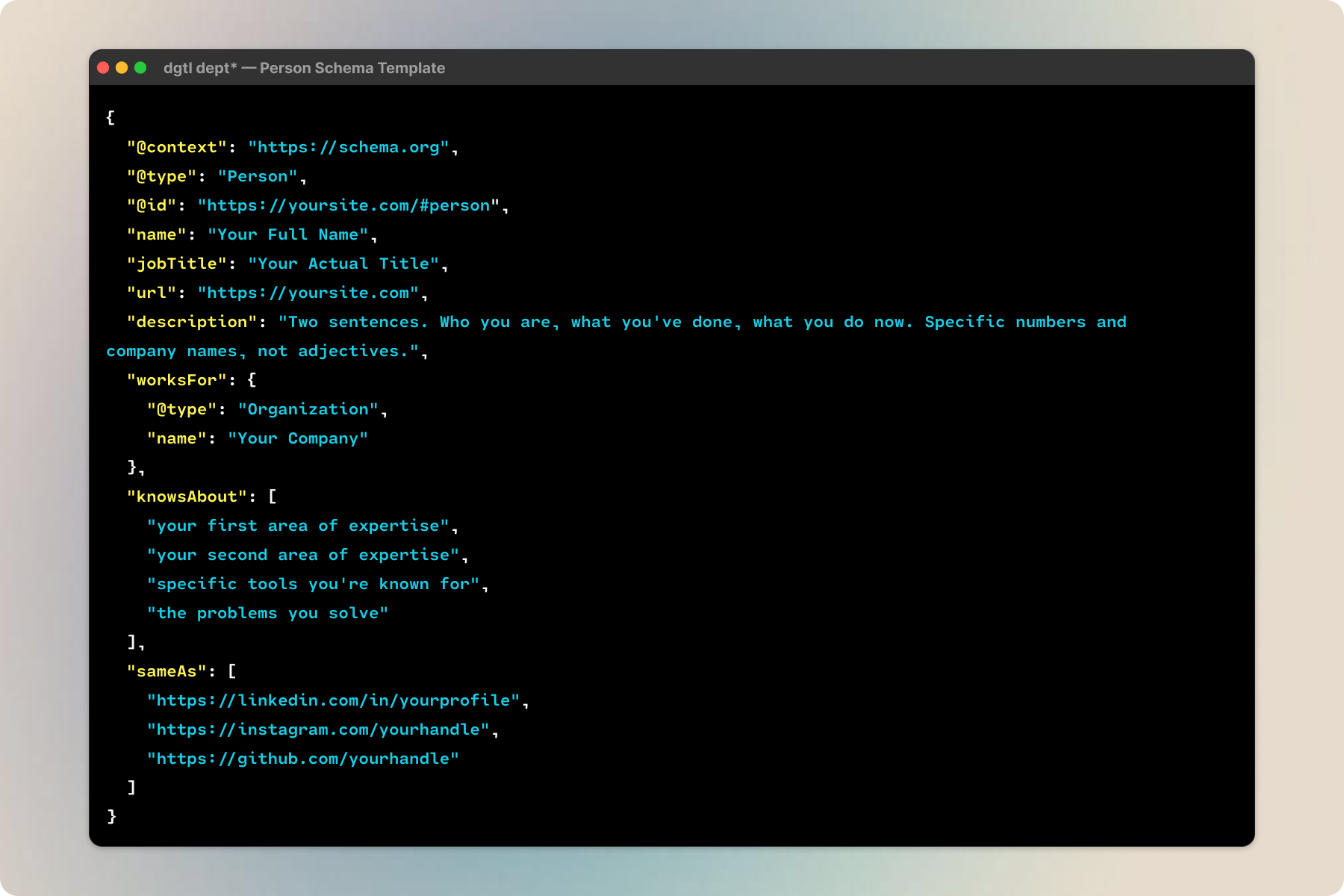
Person schema is the core identity block. Your name, title, career description, knowsAbout terms for your expertise areas, and sameAs links to your profiles elsewhere. Mine has 21 expertise terms and links to LinkedIn, Substack, Crunchbase, Clay.earth, Figma, etc. The @id creates a canonical URL for your identity that everything else references back to. It’s what turns scattered mentions into one entity.
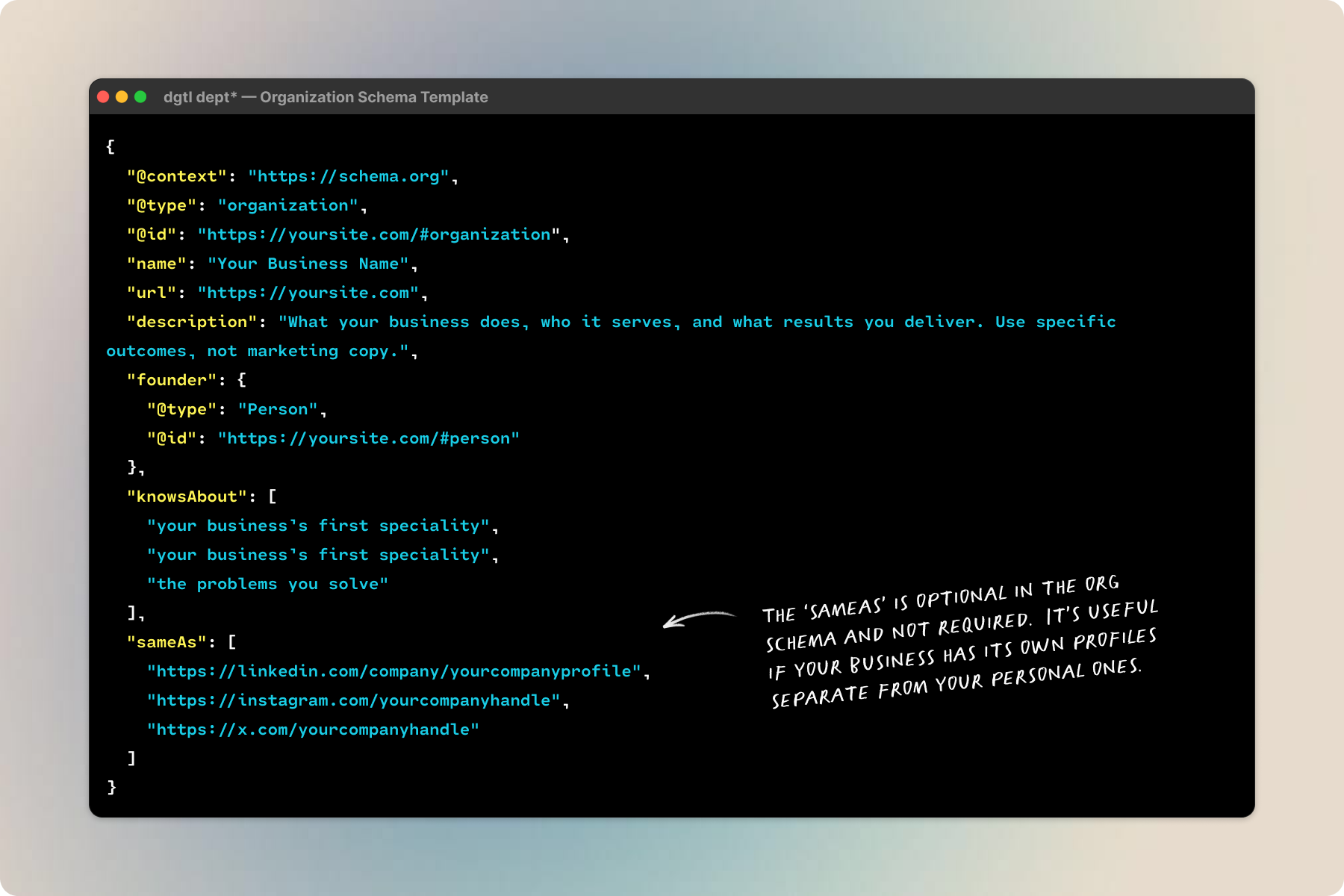
Organization schema is if you run a business or consultancy, this connects it to your Person. I added one for RRBC (my consulting practice) linked back to me as founder. Without it, AI crawlers had no way to connect “RRBC” to “Rebecca Barton.” If you’re a solo consultant or freelancer, this is how your business name and your name are connected.
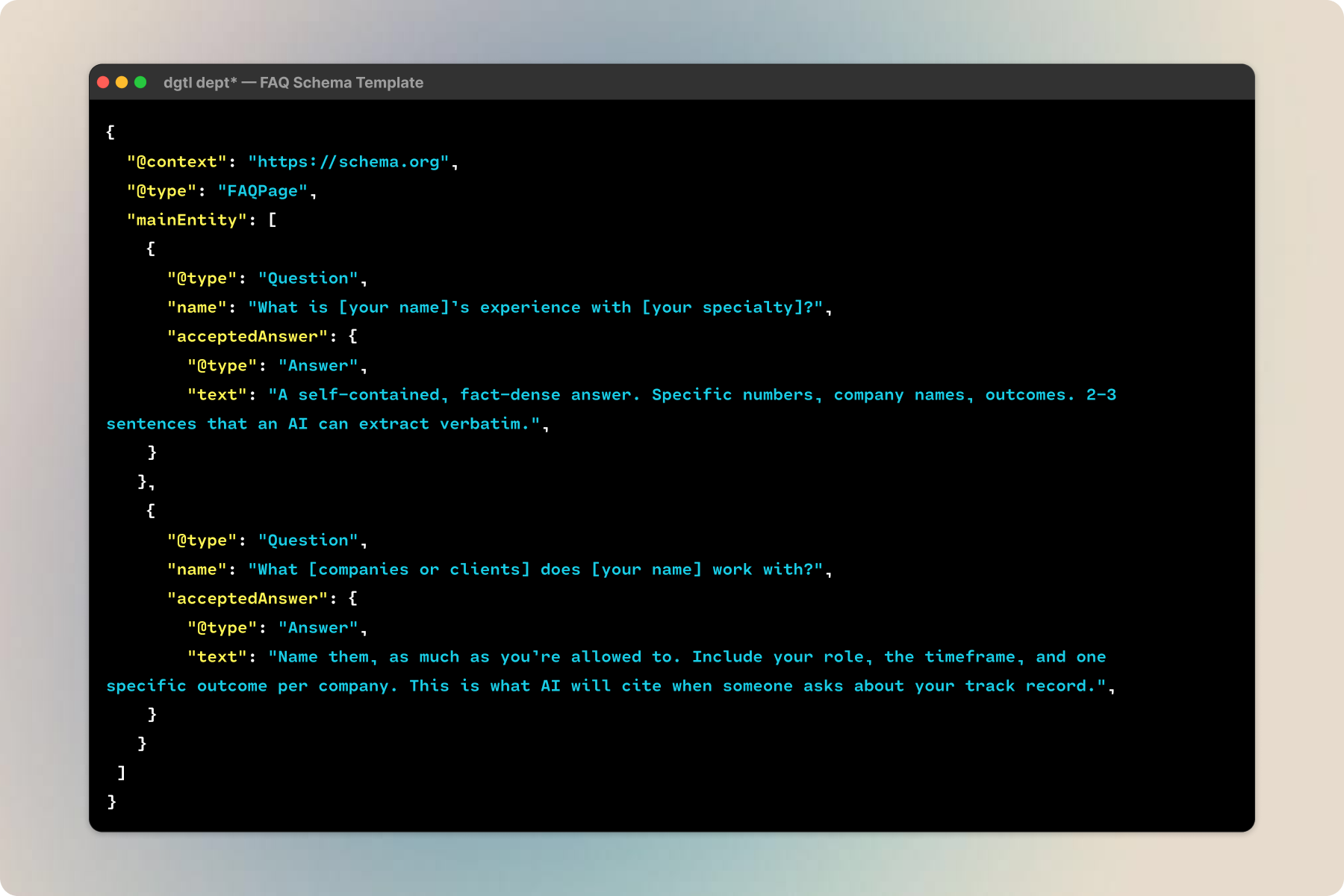
FAQ schema is just question-and-answer pairs that LLMs can extract and cite directly. These are the questions someone would ask an AI about you: what’s your specialty, what companies have you worked with, what tools do you use, what results have you delivered. Each answer is a self-contained, fact-dense passage the AI can pull into a response verbatim. I wrote mine based on what the models were getting wrong in my initial audits — they were guessing my tech stack, so I wrote the correct one into an FAQ answer and gave them something accurate to cite instead.
Your version: If your site runs on Framer, Squarespace, WordPress, or anything that lets you edit the <head>, you can add Person schema today. Here’s a minimal version:
{
"@context": "https://schema.org",
"@type": "Person",
"@id": "https://yoursite.com/#person",
"name": "Your Full Name",
"jobTitle": "Your Actual Title",
"url": "https://yoursite.com",
"description": "Two sentences. Who you are, what you've done, what you do now. Specific numbers and company names, not adjectives.",
"worksFor": {
"@type": "Organization",
"name": "Your Company"
},
"knowsAbout": [
"your first area of expertise",
"your second area of expertise",
"specific tools you're known for",
"the problems you solve"
],
"sameAs": [
"https://linkedin.com/in/yourprofile",
"https://twitter.com/yourhandle",
"https://github.com/yourhandle"
]
}Paste that inside a <script type="application/ld+json"> tag at then end of your page’s <head>. Start with whatever you have — mine has 21 knowsAbout terms and links to five platforms, but even a few is better than nothing. Google’s Rich Results Test validates the schema once it’s live. The Person type on Schema.org has the full property list.
Structured data on platforms you don’t control
I publish on Substack at dgtl dept (you’re here, reading it). Substack gives me a title field, a description field, a slug, some SEO options for an alternative title and description, but that’s it. No custom <head> tags. No JSON-LD injection.
So I built an edge proxy.
If you’re not technical, don’t fret. The proxy pretty simple, despite what it looks like, and I’ve open-sourced a Claude Code skill pack which includes the template, step by step instructions, and prompts for you, here.
Bonus: Running the edge proxy for Substack through Vercel’s free tier allows you to get around that $50 custom domain fee Substack likes to surprise folks with.
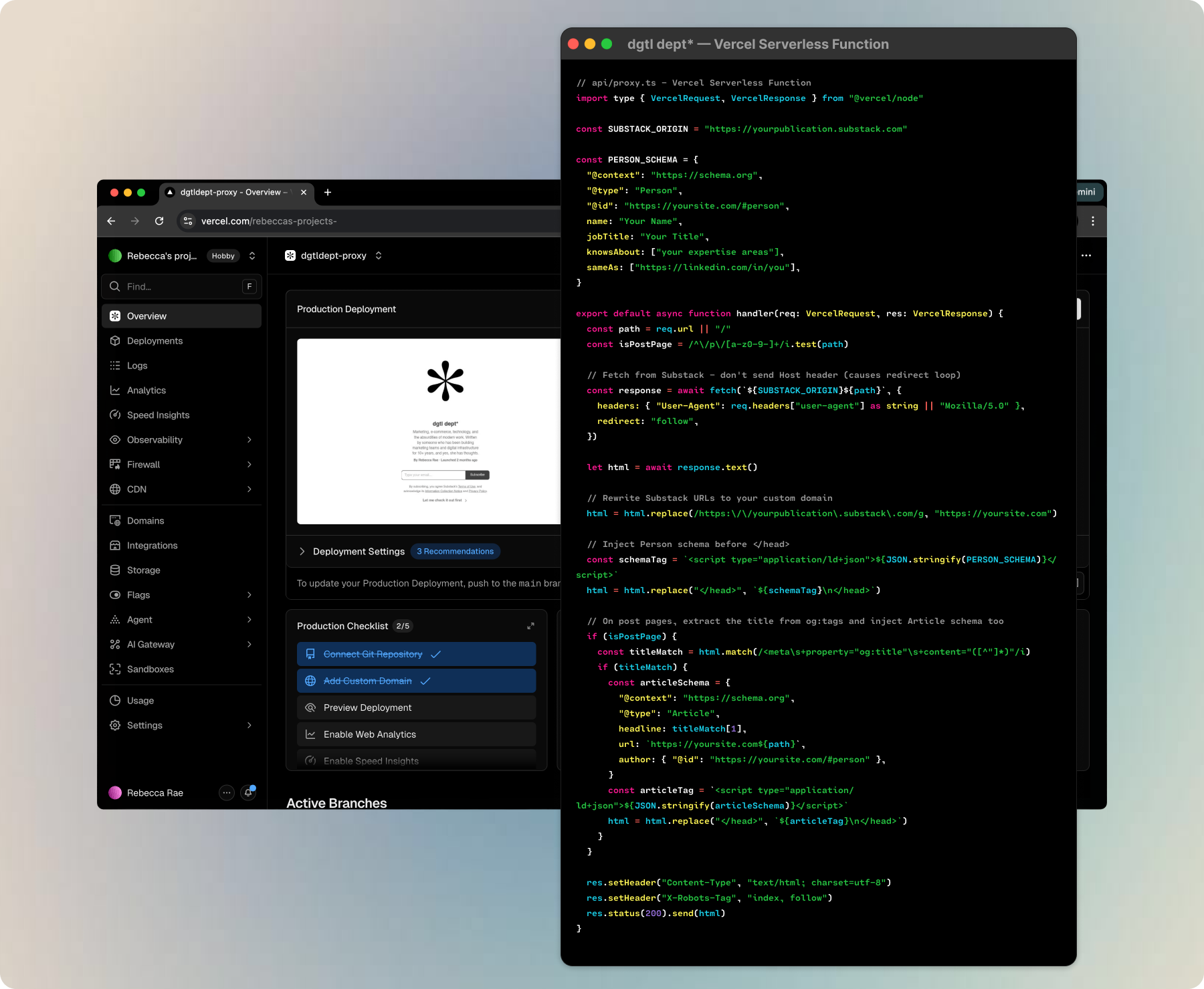
The proxy sits on Vercel between the reader and Substack. When someone requests a page from dgtldept.com, the proxy fetches the page from Substack, injects structured data into the HTML, and serves the enhanced version. The reader sees normal Substack. The AI crawler sees a fully structured page with three layers of schema:
Person schema on every page. This is the anchor. Name, job title, knowsAbout terms, and sameAs links pointing to LinkedIn, GitHub, and a personal site. A canonical @id ties every piece of content on your substack back to you as a named entity in the knowledge graph, just like we did before.
WebSite schema on the homepage. Publication name, description, publisher and author linked back to the Person entity.
Article schema on every post. Headline and description extracted from Substack’s Open Graph meta tags, author linked to the Person entity. Every essay I publish automatically inherits the full entity context.
The proxy took ~2 hours to build and verify.
High-authority profiles, one sitting
This was the “one sitting” phase. I created or claimed profiles on every high-authority platform that AI crawlers index:
GitHub: a personal profile for me and an organization page for dgtl dept that includes a Pages site that includes Organization, Person, and WebSite JSON-LD schemas. DA 96.
Crunchbase: a personal profile with current role, company, and career history. DA 91, heavily crawled.
Qwoted and Connectively (the HARO successor): expert source platforms where journalists find people to quote. Every published quote creates a third-party citation linking my name to my expertise areas.
Each profile uses the same canonical bio, the same title, the same expertise framing. The goal isn’t to be active on all these platforms. It’s to create indexed nodes across high-authority domains that all point back to the same entity.
Your version: Pick 2-3 high-authority platforms and create or claim your profile this week. GitHub (DA 96), Medium (DA 95), About.me (DA 92), and Crunchbase (DA 91) are the highest-leverage. Use the same canonical bio everywhere. One sitting.
You can tell AI it’s wrong about you
This one surprised me. When I audited what each AI model said about me, three of the four had specific factual errors: fabricated tool proficiencies (ChatGPT invented that I use HubSpot and Hootsuite — I don’t), incorrect employer names, reversed career chronology, and in one case, Google AI Mode had to disambiguate me from a romance novelist who writes stories set in Italy.
Every major AI platform has a process for requesting factual corrections. I drafted specific messages to OpenAI, Anthropic, Perplexity, Google, and even MapQuest of all places — each citing the exact errors, providing the correct information or asking for removal, and linking to verification sources. This took about an hour. The corrections propagated within 2-4 weeks. Unsurprisingly, MapQuest took the longest.
Most people don’t know this is an option. It is. If an AI is saying wrong things about you, you can ask them to fix it.
Your version: After your diagnostic, document every factual error, if you have any. Then submit corrections:
OpenAI (ChatGPT): OpenAI Privacy Portal
Anthropic (Claude): usersafety@anthropic.com
Perplexity: support@perplexity.ai
Google (Gemini): In-product feedback button
Cite the exact error, provide the correct information, and link to your verification sources (personal site, LinkedIn).
This took about an hour. The corrections propagated within 2-4 weeks. Unsurprisingly, MapQuest took the longest.
The final cheat sheet
Create a personal llms.txt file. This is a specification from Jeremy Howard at Answer.AI that gives AI crawlers a structured, markdown-formatted manifest of your site: what it is, what it covers, and where to find the important pages.
About 951 domains had published an llms.txt file as of mid-2025. That number has since jumped to over 844,000, an 888x increase driven by platforms like Mintlify mandating it across their networks. The window for early differentiation is closing. It hasn’t closed. Sites with llms.txt are seeing 30-70% higher accuracy in AI-generated summaries of their content.
Mine covers the publication description, topic areas, key links, and social profiles. For a professional brand, yours should include who you are, what you write about, your most important pieces, and where else to find you.
The full spec is at llmstxt.org. 30 minutes, tops.
Your version: Here’s the format…
# Your Name
> One-sentence description of who you are and what you do.
## About
Two to three sentences. Your role, your expertise, your track record.
Specific numbers and outcomes, not marketing copy.
## Areas of Expertise
- First area (e.g., "E-commerce growth strategy and Shopify Plus")
- Second area
- Third area
## Key Content
- [Article Title](https://link): One-line description
- [Article Title](https://link): One-line description
## Find Me
- Website: https://yoursite.com
- LinkedIn: https://linkedin.com/in/yourprofile
- Publication: https://yoursubstack.com
Host it at yourdomain.com/llms.txt. The full spec is at llmstxt.org. 30 minutes, tops.
One node, not multiple fragments
The schema, the llms.txt, the platform profiles — all of that is infrastructure. Entity consistency is what makes it work.
LLMs cross-reference you across the entire internet. If your name, title, bio, and areas of expertise are inconsistent across your website, LinkedIn, GitHub, Substack, and any other platform where you have a presence, the AI can’t confidently build a picture of who you are. It sees fragments that might or might not be the same person and will make a decision in the moment if you are the same person.
I audited my own presence and found inconsistencies I’d never noticed. Different job titles across platforms. A LinkedIn headline emphasizing something different than my Substack bio. A long abandoned Twitter account bio that was out of date. Humbling, for someone who works on the internet for a living, honestly.
None of this mattered for human readers who could piece together the context and see that I hadn’t been active since 2017, but all of it mattered for a machine trying to construct a canonical entity.
The fix: write one canonical bio and propagate it everywhere. Make your sameAs links explicit in your Person schema. Use the same name formatting on every platform. Align your stated expertise. The machine builds a graph. You need to be one node in it, not five disconnected fragments.
Your version: Open all your profiles in separate tabs and compare four things:
Name: Same formatting everywhere? “Rebecca Barton” on one platform and “Rebecca Rae Barton” on another splits your entity. I know from experience.
Title: Same job title, or does LinkedIn say one thing and your website say another?
Expertise framing: Are you “a marketing executive” on LinkedIn, “a consultant” on your website, and “a writer” on Substack? Pick one and propagate.
Cross-links: Does your LinkedIn link to your website? Does your website link back? Every missing link is a gap in the entity graph.
Your simple workflow: start here today
Step one: Run the diagnostic. Open incognito windows in ChatGPT, Claude, Perplexity, and Gemini. Ask each one about yourself by name. Ask follow-ups about your area of expertise. Screenshot and/or copy the text results and save them away. This is your baseline, and honestly, the results will motivate everything else. Be sure to use the same prompt when you re-test every week or so, so your input stays consistent and the output is measurable.
Step two: Run the entity audit. Open every platform where you have a presence in separate tabs. Compare name, title, expertise framing, and cross-links. Write one canonical bio and update every platform to match it. This takes an afternoon.
Step 3: Check what’s blocking you. If you have a personal site, check your robots.txt for AI crawler directives. You want this:
User-agent: GPTBot
Allow: /
User-agent: ClaudeBot
Allow: /
User-agent: PerplexityBot
Allow: /
User-agent: Google-Extended
Allow: /
If you’re on Substack, check the “Block AI training” toggle in settings. That toggle blocks all AI crawlers, including the retrieval bots that would actually send readers your way. Many Substack writers have it on without realizing what it does.
Step four: Add Person schema to a site you control. Even a single static page on Carrd or GitHub Pages with JSON-LD in the <head>. Validate with Google’s Rich Results Test. The template is in the Structured Data section above.
Step five: Build your llms.txt. Host it at yourdomain.com/llms.txt. The template is in the llms.txt section above. 30 minutes.
Step 6: Rewrite your About pages. Every platform bio, Substack about page, personal website. Front-load credentials. Specific numbers, named companies, current role. Lead with the thing you want AI to know about you.
Step 7: Submit correction requests. If any AI said something wrong about you in the diagnostic, draft the correction messages. The contact info is in the Correction Messages section above. Budget an hour. They propagate in 2-4 weeks.
Step 8: Claim high-authority profiles. GitHub, Crunchbase, any expert source platforms relevant to your field. Same canonical bio everywhere.
Important notes:
The ongoing cost is effectively zero. The alternative was hoping the platforms you publish on would eventually implement structured data on your behalf. Spoiler: they won’t. LinkedIn has no incentive to make your profile data portable to competing AI systems. Substack has other priorities. Own the pipes.
AI is a tool, not a business strategy. The business owners I see getting the most value from Claude are the ones who already know what they are building and use AI to build it faster. If you do not have clarity on your goals, offers, your audience, and your positioning, figure that out first, then come back.
Your data is your responsibility. You have to read the privacy settings. Understand what you are uploading and presenting to these models. We all know the internet is forever.
Success is subjective. I can’t give you a clean before-and-after metric. AEO measurement is immature, particularly if you’re not selling anything. There’s no Search Console for AI citations, and ChatGPT strips referrer data. What I can tell you is that the infrastructure either exists or it doesn’t, and when someone asks an AI about your domain of expertise, you’ll either be structurally legible or you won’t.
This is a compound play. The people building this layer now will compound visibility while everyone else wonders why they’re not showing up in LLM responses, either as a brand or individual. AEO is still in its infancy, and I’d rather be learning and capitalizing while the playing field isn’t too crowded.
One last thing, for the skeptics: “I’m not famous enough for AI to cite me” is the wrong frame. AEO has nothing to do with fame. It’s about being structurally citable when someone asks a question you’re qualified to answer. The infrastructure either exists or it doesn’t. If it doesn’t, you’re not even in the running.
If you found this useful, or if any of these tools sparked something, reply and tell me — I read everything. You may have noticed that dgtl dept* is getting a bit of a glow up at the moment and I have a lot more content for subscribers soon as I consolidate my work and aim to provide you with the best resources on how to practically use AI in your business and life.
You can upgrade to paid for less than an iced matcha each month and get access to everything as soon as it lands, as well as the complete archive.